SIGMA课题组五篇论文被CCF A类会议/期刊录用
近日,国际人工智能领域顶级期刊《IEEE Transactions on Pattern Analysis and Machine Intelligence》(IEEE TPAMI, IF=24.314)在线刊发了团队叶茫教授、杜博教授题为“Federated Learning for Generalization, Robustness, Fairness: A Survey and Benchmark”的论文,联合学习已成为各方之间隐私保护协作的一种有前景的范式。
最近,随着联合学习的普及,许多方法已经为不同的现实挑战提供了解决方案。在这项调查中,我们系统地概述了联邦学习研究的重要和最新进展。首先,我们介绍了该领域的研究历史和术语定义。然后,我们通过介绍各自的背景概念、任务设置和主要挑战,全面回顾了三条基本的研究路线:泛化、鲁棒性和公平性。我们还提供了关于方法和数据集的代表性文献的详细概述。我们在几个著名的数据集上进一步对所审查的方法进行了基准测试。最后,我们指出了该领域的几个悬而未决的问题,并提出了进一步研究的机会。我们还提供了一个公共网站,以不断跟踪这一快速发展领域的发展。论文的第一作者为黄文柯博士,通讯作者为叶茫教授。该研究工作得到国家自然科学基金、国家科技部重点研发计划项目等项目的资助。
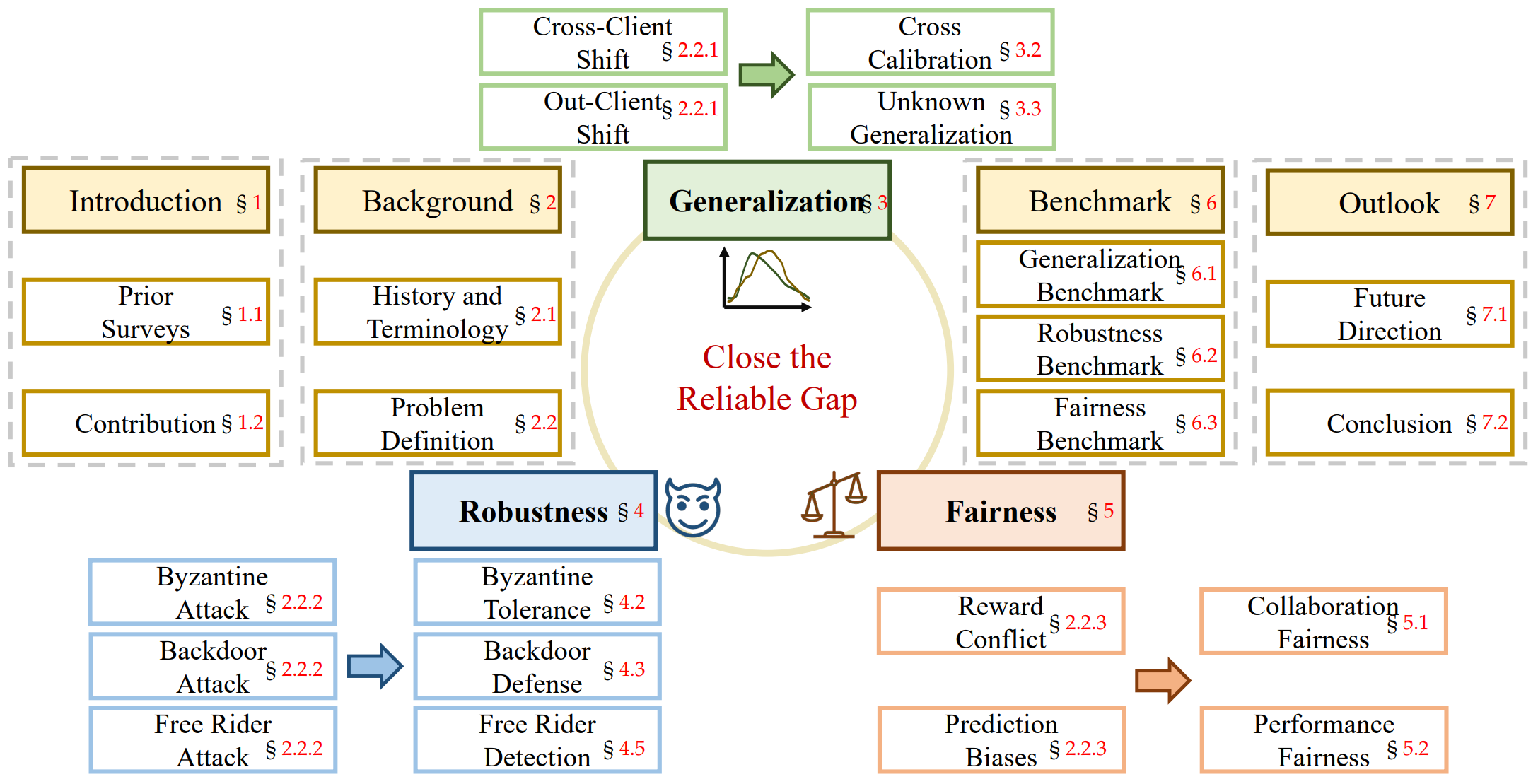
综述框架
算法性能比较
代码链接: https://github.com/WenkeHuang/MarsFL
论文链接: https://ieeexplore.ieee.org/document/10571602
我组以2020级博士生唐安科、2021级博士生王云柯、2023级博士生黄文柯和张子屹为第一作者的4篇论文被国际机器学习大会(The International Conference on Machine Learning ,简称ICML)2024录用。ICML是机器学习与人工智能领域的国际顶级学术会议,是机器学习领域历史最悠久的、规模最大、影响最广的顶级学术会议之一,也是中国计算机学会CCF推荐的A类会议。本届会议共收到有效论文投稿9473篇,其中有2609篇论文被录用,录用率为27.5%。
论文题目:Imitation Learning from Purified Demonstrations
作者:Yunke Wang, Minjing Dong, Yukun Zhao, Bo Du, Chang Xu
指导老师:杜博教授
论文概述:模仿学习是一种通过观察专家行为来学习如何完成任务的机器学习方法,广泛应用于机器人和自动驾驶等领域,使智能体通过模仿人类或专家的操作来提高性能。模仿学习算法通常假设专家演示是最优的,然而在实际任务中,专家演示往往存在不完美之处,这给算法带来了挑战。为了解决这些问题,本文提出了一种基于扩散过程的通用去噪算法,用于预处理不完美的专家演示,以增强后续模仿学习策略的学习。受到扩散模型成功的启发,本文设计了两步扩散去噪过程。首先,前向扩散过程通过引入额外的高斯噪声来平滑演示中的潜在噪音;接着,反向扩散过程用于重建最优专家演示。理论分析证明了重建后的演示与最优演示之间的距离有明确的上下界,且最优扩散时间步的大小与演示中潜在噪声的程度正相关。在MuJoCo基准任务中的实验结果验证了提出算法的有效性,亦验证了理论证明中关于最优时间步的分析。
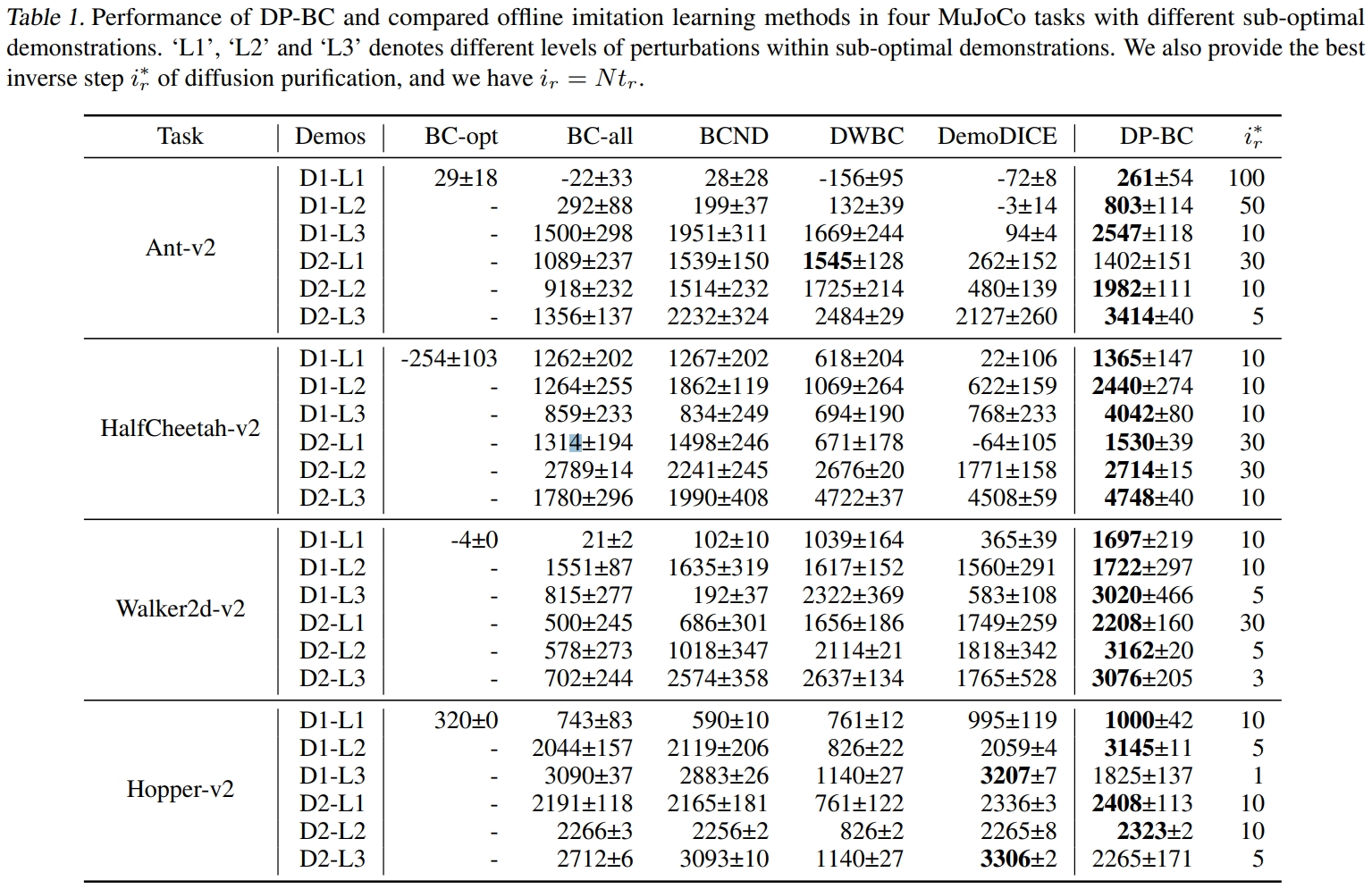
算法性能比较

最优时间步分析
代码链接: https://github.com/yunke-wang/dp-il
论文链接: https://openreview.net/forum?id=dyfsPNuYCk
论文题目:Self-Driven Entropy Aggregation for Byzantine-Robust Heterogeneous Federated Learning
作者:Yunke Wang, Minjing Dong, Yukun Zhao, Bo Du, Chang Xu
指导老师:叶茫教授、杜博教授
论文概述: 联合学习为隐私友好型协作提供了巨大的潜力。然而,联邦学习受到拜占庭式攻击的严重威胁,恶意客户端故意上传精心制作的恶意更新。虽然已经提出了各种反破产聚合来防御此类攻击,但它们受到某些假设的约束:同质的私有数据和重复的代理数据集。为了解决这些局限性,我们提出了自驱动熵聚合,它利用随机公共数据集在异构联邦学习中进行拜占庭式鲁棒聚合。对于拜占庭攻击者,我们观察到,在公共数据集上,良性攻击者通常比邪恶攻击者提供更自信(更清晰)的预测。因此,我们通过引入可学习的聚合权重来最小化随机公共数据集上全局模型的实例预测熵,从而突出良性客户端。此外,由于固有的数据异构性,我们发现它带来了异构锐度。具体来说,客户在不同的分布下进行了优化,从而呈现出富有成效的预测偏好。可学习的聚合权重盲目地将高度注意力分配给有限的权重,以获得更准确的预测,从而导致有偏见的全局模型。为了缓解这个问题,我们鼓励全局模型通过批量预测熵最大化提供多样化的预测,并进行聚类以平均分配诚实权重以适应不同的趋势。这使得SDEA能够在异构联邦学习中检测拜占庭攻击者。实证结果证明了该方法的有效性。

算法的框架图

算法的定量实验
代码链接: https://github.com/WenkeHuang/SDEA
论文链接: https://openreview.net/forum?id=k2axqNsVVO
论文题目:Confronting Reward Overoptimization for Diffusion Models: A Perspective of Inductive and Primacy Biases
作者:Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
指导老师:罗勇教授、杜博教授
论文概述:本研究提出了一种面向扩散模型的强化学习微调训练方法——TDPO-R(Temporal Diffusion Policy Optimization with critic active neuron Reset),旨在解决强化学习过程中面临的奖励过优化问题,即模型过度追求奖励函数最大化而偏离人类的实际偏好。具体来说,奖励过优化这一问题通常表现为:模型获得的奖励提升至一定临界值时,其生成图像的保真度或多样性严重损失,且其跨奖励泛化能力逐渐下降。具体地,TDPO-R算法提出了两项创新策略:(1)时间差分奖励机制:TDPO-R通过引入时间归纳偏置,将奖励函数分解为多个时间差分奖励,从而为扩散模型在每个生成步骤提供更加细粒度的优化指导,有效缓解了因偏置错位导致的奖励过优化问题;(2)活跃神经元重置策略:TDPO-R还通过周期性地重置评判器模型中的活跃神经元,来消除首要偏置(Primacy Bias)对优化过程的负面影响,避免由模型过度依赖早期训练经验而导致的奖励过优化问题。与此前先进的强化学习和监督学习微调训练方法相比,TDPO-R在样本效率和跨奖励泛化之间的权衡方面具有显著优势,有效地缓解了奖励过优化的问题,帮助模型生成更加符合人类实际偏好的图像。

TDPO-R算法的基本流程

跨奖励泛化度量对比
代码链接: https://github.com/ZiyiZhang27/tdpo
论文链接: https://proceedings.mlr.press/v235/zhang24ch.html
论文题目:Merging Multi-Task Models via Weight-Ensembling Mixture of Experts
作者:Anke Tang, Li Shen, Yong Luo, Nan Yin, Lefei Zhang, Dacheng Tao
指导老师:罗勇教授、张乐飞教授
论文概述:本研究提出了一种新型的基于混合专家的模型融合方法,特别应用于 Vision Transformer 视觉模型。在大模型的应用时代,通过在下游任务上进行模型微调,可以显著提升大模型在特定任务中的表现。相较于从头开始训练模型,微调策略已经逐渐成为主流。微调不仅能够提高模型性能,还能实现高效的知识迁移,从而构建多任务模型。然而,在某些情况下,如下游任务数据受到隐私保护限制,无法集中训练多任务大模型;或者为了节省训练多任务模型所需的计算资源。具体来说,可以选择复用现有的单任务模型。在本研究中,通过构建参数集成的混合专家模块,实现识别和分离共享知识与特定下游任务的知识,并根据输入的不同动态整合这些知识。论文提出的基于参数集成的混合专家模型能够针对每个实例的具体需求进行调整,从而显著减少各个单任务模型之间的参数干扰问题。通过这种方式,不仅能提高模型在多任务环境中的性能,还能有效利用现有资源。
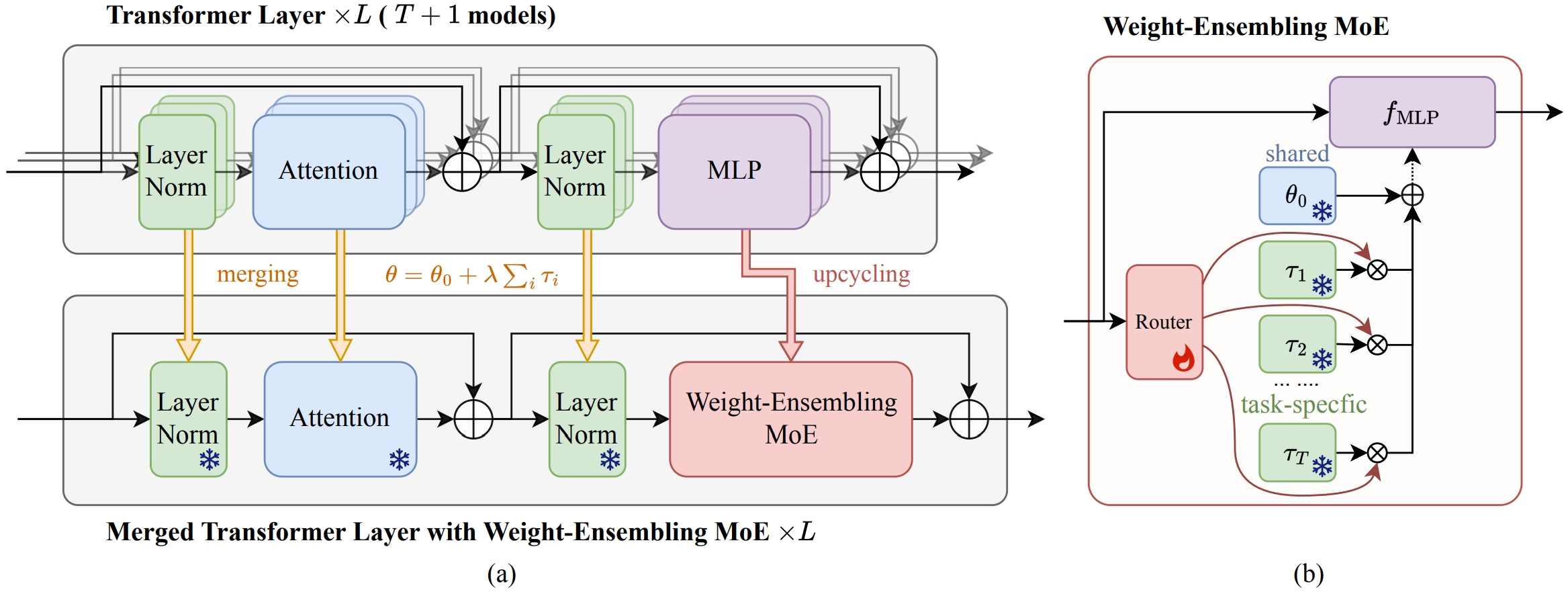
基于参数集成的混合专家模块

ViT-B/32 模型进行模型融合算法性能比较

ViT-L/14 模型进行模型融合算法性能比较