Sigma研究组8篇论文被多媒体顶级会议ACM MM2022录用
Sigma研究组博士后陈翠群、20级博士生韩梦雅、21级博士生李贺、21级硕士生陈朔怡和黄文柯、21级硕士生黄木琪、18级本科生施武轩、19级本科生张俊武为第一作者的8篇论文被多媒体领域顶级会议ACM MM2022录用。
ACM International Conference on Multimedia (简称ACM MM)是国际多媒体领域学术和产业界交流的最顶级盛会,也是中国计算机学会推荐的多媒体领域唯一的A类国际学术会议。会议将于2022年10月10日至10月14日在葡萄牙里斯本举行。
论文介绍:
论文题目: Rotation Invariant Transformer for Recognizing Object in UAVs
作者: Shuoyi Chen, Mang Ye, Bo Du
指导教师:叶茫教授,杜博教授
工作简介:无人机场景下的目标检索任务是一个在无人机动态拍摄的图像或视频序列中识别特定目标的任务。相比于普通城市监控摄像头场景,无人机场景的目标检索面临生成的目标边界框差异大,背景噪声多,目标多种旋转角度变化等问题。然而现有方法都是为城市摄像头场景设计,难以解决上述问题,在无人机场景中性能急剧下降。这项工作中,我们提出了无人机场景下基于Transformer的旋转不变目标检索方法:借助视觉Transformer的结构特性,通过在特征层面模拟旋转操作获得多个旋转特征来达成旋转多样性。同时,通过建立原始特征和旋转特征之间的约束进一步实现旋转不变性,增强模型对无人机场景下目标角度变化的泛化能力。在多个无人机收集的行人、车辆数据集上采用我们的方法,实验效果显著提升。
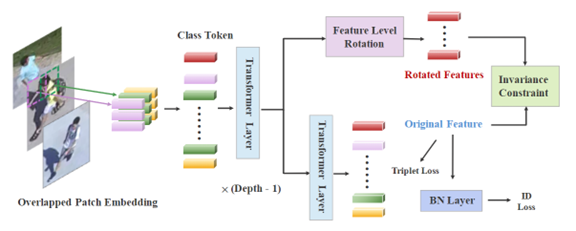
图1 算法模型框架图
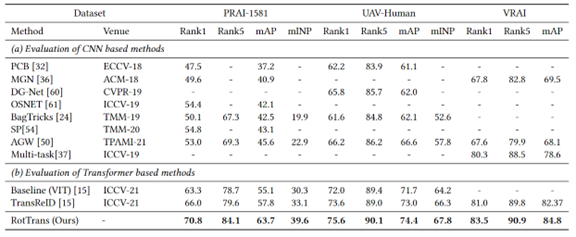
图2 算法的定量结果
论文题目:Sketch Transformer: Asymmetrical Disentanglement Learning from Dynamic Synthesis
作者: Cuiqun Chen, Mang Ye, Meibin Qi, Bo Du
指导教师:叶茫教授
工作简介:素描-照片识别是一类跨模态匹配问题,其查询集是由专业或业余画家绘制的素描图像。现有的方法主要通过探索模态不变性特征来挖掘共享特征嵌入空间。然而,这些方法未考虑到两种模态间的信息非对称性问题,提取的特征鉴别力有限。本文基于Transformer框架提出一种新的非对称分解和动态合成学习方法(SketchTrans),通过将模态共享信息与模态特定信息相结合来处理模态差异。具体地,我们引入一种非对称分解方案,该方案将照片特征分解为与素描相关和素描不相关的表征。同时,利用与素描不相关表征,通过知识迁移方法,进一步将素描模态表征转化为照片表征,获得具有信息对称性的跨模态表征。此外,为实现照片表征的精准分解,我们提出一种由照片模态生成的可动态更新的辅助素描模态(A-sketch)。该模态具有与手绘素描模态相似的图像风格,同时保持了与照片模态相同的结构信息。在多模态联合学习框架下,A-sketch模态增加了训练样本的多样性,缩小了跨模态差异。我们在三个细粒度的基于素描图的检索数据集(即PKU-Sketch,QMUL - Chairv2和QMUL - Shoev2)上进行了广泛实验,各项指标下的模型性能均优于最先进方法。

图1 算法模型框架图

图2 在ChairV2(上)和PKU-Sketch(下)数据集上的定性检索结果
论文题目:Symmetric Uncertainty-Aware Feature Transmission for Depth Super-Resolution
作者: Wenke Huang, Mang Ye, Bo Du
指导教师:叶茫教授, 杜博教授
工作简介:由于深度传感器成像能力的限制,深度图的分辨率通常很难与RGB图像匹配,这限制了它的实际应用。颜色引导的深度超分辨率是一项实用且有价值的任务,它利用同一场景中的超高分辨率RGB图像来引导低分辨率深度图的增强。现有的方法通常在将深度图送入网络之前使用插值对其进行放大,并传递从高分辨率RGB图像中提取的高频信息以指导深度图的重建。然而,由于存在跨通道差异,提取的高频信息通常包含在深度图中不存在的纹理,并且因为RGB图像和深度图之间的分辨率差异,前置插值会进一步加剧噪声。为了应对这些挑战,我们提出了一种新的Symmetric Uncertainty-aware Feature Transmission (SUFT)模块。(1)对于分辨率差异,SUFT构建了一个迭代式上下采样流水线以替换常用的前置插值上采样,使深度特征和RGB特征在空间上保持一致,同时抑制噪声放大和模糊。(2)对于跨通道差异,我们提出了一种新的对称不确定性方案,去除了不利于HR深度图恢复的部分RGB信息。在基准数据集和具有挑战性的真实世界设置上的广泛实验表明,我们的方法与最先进的方法相比具有更好的性能。
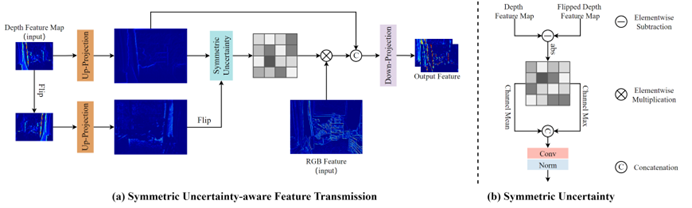
图1 本文提出的SUFT示意图

图2 与SOTA方法比较的实验结果
论文题目:Pyramidal Transformer with Conv-Patchify for Person Re-identification
作者:He Li, Mang Ye, Cong Wang, Bo Du
指导教师:叶茫教授,杜博教授
工作简介:提取鲁棒且具有判别力的特征是行人重识别任务中的关键技术。传统的卷积神经网络受限于其感受野大小,无法学习到距离较远且离散的信息特征;普通的Transformer网络则对平移和视角变换敏感,并且由于分块操作导致无法学习到细粒度的特征。在这项工作中,我们针对以上问题在金字塔结构的Transformer的基础上提出了以下几点改进:(1)利用带有低通滤波器以及全尺寸填充的重叠卷积替代分块操作以提升平移等效性,学习分块内部特征,减少边缘信息丢失问题,并隐式的学习位置信息而无需位置编码;(2)利用透视变换对特征进行增广,模拟、学习不同视角和尺度下的局部特征;(3)以类似位置编码的形式,利用辅助信息进一步提升特征判别力,降低非视觉信息对特征的干扰。在多个行人重识别数据集上的实验结果验证了我们方法和各个模块的有效性。
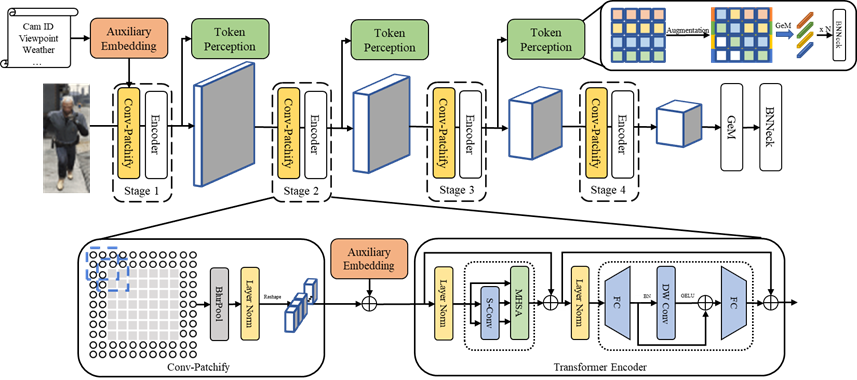
图 1算法模型的框架图
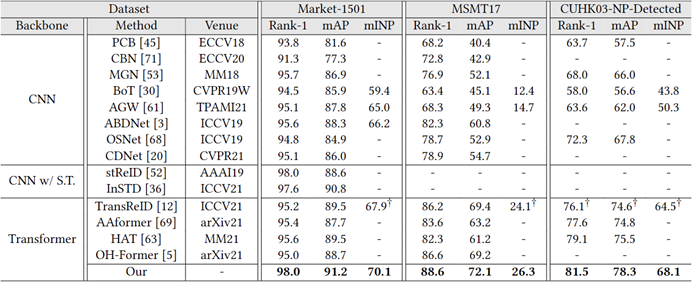
图 2与SOTA方法比较的实验结果
论文题目:Few-Shot Model Agnostic Federated Learning
作者:He Li, Mang Ye, Cong Wang, Bo Du
指导教师:叶茫教授,杜博教授
工作简介:联合学习因其在不泄露隐私的情况下进行协作学习的能力而受到越来越多的关注。但是现有方法通常假设参与者共享相同的模型结构的情况。然而,当参与者独立地定制他们的模型时,模型会遇到通信交流展给,导致模型异构问题。此外,在实际场景中,参与者持有的数据往往有限,使得仅基于私有数据训练的局部模型表现不佳。因此,本文研究了一个新颖的且具有挑战性的问题,即少样本模型不可知联邦学习,其中本地参与者从其有限的私有数据集设计其独立的模型。考虑到私人数据的稀缺性,我们建议利用丰富的公共可用数据集来弥合本地私人参与者之间的差距。然而,它的使用也带来了两个问题:标签不一致以及公共和私有数据集之间存在较大领域差异。为了解决这些问题,本文提出了一个包含两个主要部分的新框架:1)模型无关联邦学习,它通过统一共享公共数据集上的模型预测输出来执行通信交流;2) 潜在嵌入自适应,它通过对抗式学习方案来解决域差距,以区分公共域和私有域。结合理论泛化界分析,在各种环境下的综合实验验证了我们优于现有方法。它为未来的发展提供了一个简单但有效的基线方案。
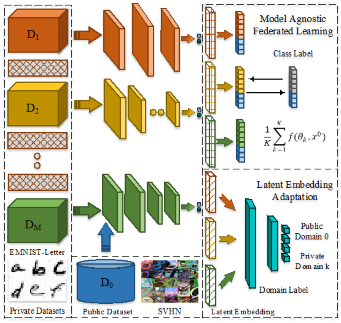
图 1算法模型的框架图

图2 算法的定量结果
论文题目: Learnable Privacy-Preserving Anonymization for Pedestrian Images
作者: Junwu Zhang, Mang Ye, Yao Yang
指导教师: 叶茫教授
工作简介:由于原始行人图像包含敏感的身份信息,因此从数据层面加密图像来保护个人隐私是一项十分重要的任务。传统方法一般采用马赛克、高斯模糊或加入随机噪声等措施来保护个人隐私,但是这种生硬的方法会不可避免地造成图片中语义信息的较大丢失,从而使脱敏后的行人图像无法被用于像犯罪调查等有价值的任务。在本工作中,我们提出了一种新型的匿名化框架,它通过一个由传统脱敏图像监督的GAN匿名器来匿名化原始图像,同时使用一个由原始图像监督的GAN还原器与一个行人重识别模型来联合优化匿名器,从而使得生成的匿名图像在得到视觉上隐私保护的同时,不仅能够被直接用于行人重识别任务,还能够通过授权者持有的还原器重建为原始图像用于各种视觉任务。此外,我们也提出了一种匿名器监督图像的渐进式更新策略,使匿名图像在保护隐私的同时进一步提升了其行人重识别的性能。
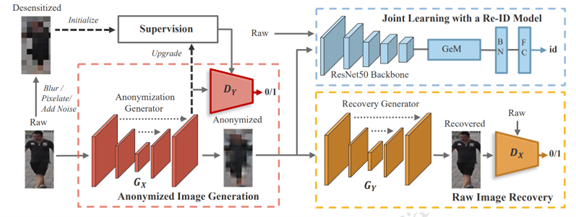
图 1算法模型的框架图
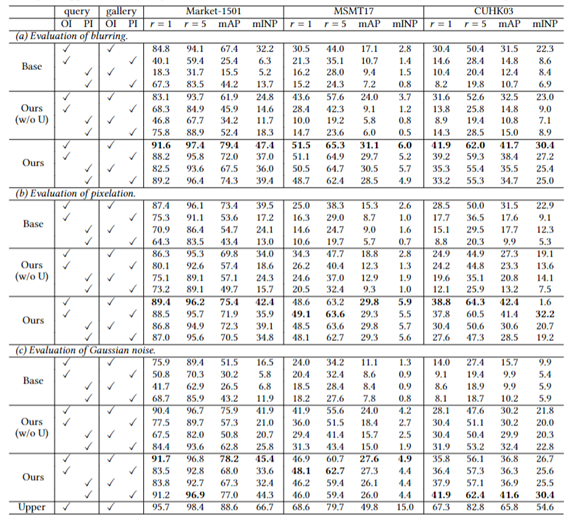
图2 算法的定量结果
论文题目: Leveraging GAN Priors for Few-Shot Part Segmentation
作者: Mengya Han, Heliang Zheng, Chaoyue Wang, Yong Luo, Han Hu, Bo Du
指导教师: 罗勇教授、杜博教授
工作简介:少样本部件分割旨在仅给定几个带标注样本的条件下来分离目标的不同部分。由于数据有限的挑战,现有的方法主要基于预训练特征学习分类器,未能学习任务特定的特征进行部件分割。在本文中,我们提出以“预训练”-“微调”的范式学习特定于任务的特征。我们进行了prompt设计以减少预训练任务(即图像生成)和下游任务(即部件分割)之间的差距,从而能够利用GAN 的先验实现分割。这是通过将部件分割图投影到 RGB 空间中并在 RGB 分割图和原始图像之间进行插值来实现的。具体来说,我们设计了一种微调策略,将图像生成器逐步调整为分割生成器,其中生成器的监督通过插值设计从原始图像变化到RGB 分割图。此外,我们提出了一个双流架构,一个用于生成任务特定特征的分割流,一个用于提供空间约束的图像流,其中图像流可以被视为一个自我监督的自动编码器,这使我们的模型能够从大规模的支持图像中受益。总的来说,这项工作是尝试通过prompt设计来探索生成任务和感知任务之间的内部相关性。大量实验结果表明,我们的模型可以在多个部件分割数据集上实现最先进的性能。

图1 算法模型框架图

图2 算法的定量结果
论文题目:Atrous Pyramid Transformer with Spectral Convolution for Image Inpainting
作者:黄木琪,张乐飞
指导教师:张乐飞教授
工作简介:图像修复的目的是将破损的图像恢复成语义合理的完整图像, Transformer可以利用其提取图像的长距离依赖性的特性,学习来自全局未损坏区域的信息来重建图像的损坏区域。在这项工作中,我们提出了一种新的基于空洞金字塔transformer结构(APT)的两阶段框架用于图像修复,逐步恢复图像的结构和纹理。具体来说,APT块的补丁以空洞金字塔逐层扩张的方式嵌入,以显式地增强窗口间和窗口内的相关性,从而更精确地恢复图像的高级语义结构,该语义图可以作为第二阶段的指导。随后,我们进一步设计了一个双谱变换卷积(DSTC)模块,协同APT来推断生成区域的低级特征。 DSTC模块将图像信号解耦为高频和低频,以全局视图捕获纹理信息。我们在数据集 CelebA-HQ、Paris StreetView 和 Places2 上对提出的方法进行修复实验,实验性能优越。
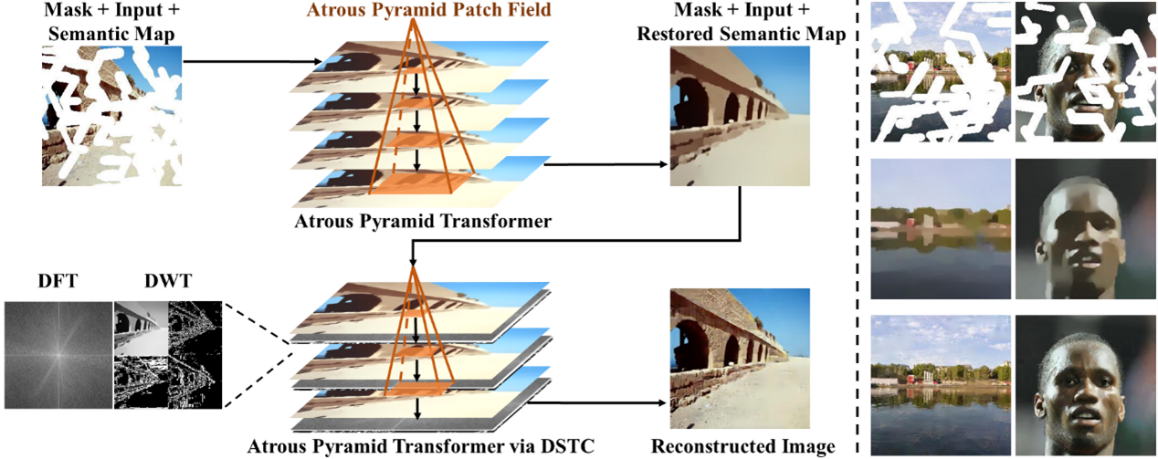
图一 算法模型示意图
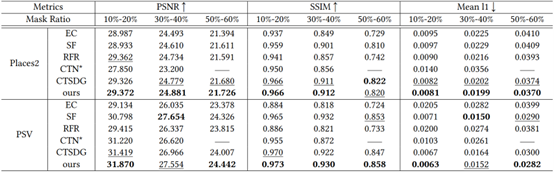
图二 算法定量对比结果
发表论文清单:
[1] Shuoyi Chen, Mang Ye, Bo Du. “Rotation Invariant Transformer for Recognizing Object in UAVs.” ACM MM2022.
[2] Cuiqun Chen, Mang Ye, Meibin Qi, Bo Du. “Sketch Transformer: Asymmetrical Disentanglement Learning from Dynamic Synthesis.” ACM MM2022.
[3] Wuxuan Shi, Mang Ye, Bo Du. “Symmetric Uncertainty-Aware Feature Transmission for Depth Super-Resolution.” ACM MM2022.
[4] He Li, Mang Ye, Cong Wang, Bo Du. “Pyramidal Transformer with Conv-Patchify for Person Re-identification.” ACM MM2022.
[5] Wenke Huang, Mang Ye, Bo Du, Xiang Gao. “Few-Shot Model Agnostic Federated Learning.” ACM MM2022.
[6] Junwu Zhang, Mang Ye, Yao Yang. “Learnable Privacy-Preserving Anonymization for Pedestrian Images.” ACM MM2022.
[7] Mengya Han, Heliang Zheng, Chaoyue Wang, Yong Luo, Han Hu, Bo Du. “Leveraging GAN Priors for Few-Shot Part Segmentation.” ACM MM2022.
[8] Muqi Huang,Lefei Zhang. "Atrous Pyramid Transformer with Spectral Convolution for Image Inpainting"ACM MM2022.