我组以20级博士生兰猛和何玥,21级硕士生陈超为第一作者的三篇论文被人工智能顶级会议AAAI 2022录用!
AAAI会议(AAAI Conference on Artificial Intelligence)是由The Associationfor Advancement of Artificial Intelligence(国际人工智能协会)每年举办的学术会议,是人工智能领域公认的权威性顶级会议。AAAI2022是第36届AAAI大会,会议将于2月22日至3月1日在线上举行。今年AAAI共收到提交的论文9251篇,其中仅1349篇论文被接受,总体接收率为15%。
论文介绍:
论文题目:Siamese Network with Interactive Transformer for Video Object Segmentation
作者: Meng Lan, Jing Zhang, Fengxiang He, Lefei Zhang
论文概述:在半监督视频目标分割中如何高效的学习和利用过去帧中目标的时空特征对于当前帧目标的分割至关重要。本文提出了一个新颖的基于交互式transformer和暹罗网络的视频目标分割框架SITVOS,交互式transformer以暹罗网路提取的当前帧和过去帧的特征作为输入,分别通过自注意力机制和互注意力机制对目标特征表达进行增强,并实现时序目标特征信息向当前帧的传播,实现对当前帧指定目标的特征增强,最后通过一个解码器完成指定目标的分割。相比于之前的基于匹配的方法,我们采用的暹罗网络在维护memory bank时可以实现特征复用,提高模型的效率。SITVOS在三个标准测试集上都达到了SOTA的性能。

图1:算法模型的框架图

图2:算法的定量结果
论文题目:Visual Semantics Allow for Textual Reasoning Better in Scene Text Recognition
作者: Yue He, Chen Chen, Jing Zhang, Juhua Liu, Fengxiang He, Chaoyue Wang, Bo Du
论文概述: 现有的场景文本识别(STR)方法通常使用语言模型来优化视觉识别(VR)模型预测的一维字符序列的联合概率, 然而忽略了字符实例内部和字符实例之间的二维空间视觉语义,使得这些方法不能很好地应用泛化到任意形状的场景文本。为了解决这个问题,本文中首次尝试利用视觉语义进行文本推理。具体而言,在给定 VR 模型预测的字符分割图,首先为每个字符实例构建一个子图,并通过根节点顺序连接合并成一个完整的图。其次基于该图,我们设计了一个图卷积网络(GTR)进行视觉文本推理。同时我们将GTR 和语言模型结构并行构建S-GTR,通过相互学习有效地利用视觉语言互补性。另外GTR 可以插入不同的STR 模型以提高其识别性能。实验证明了所提方法的有效性,S-GTR 在六个通用场景文字识别数据集上获得较好表现,并可以推广到多语言数据集。
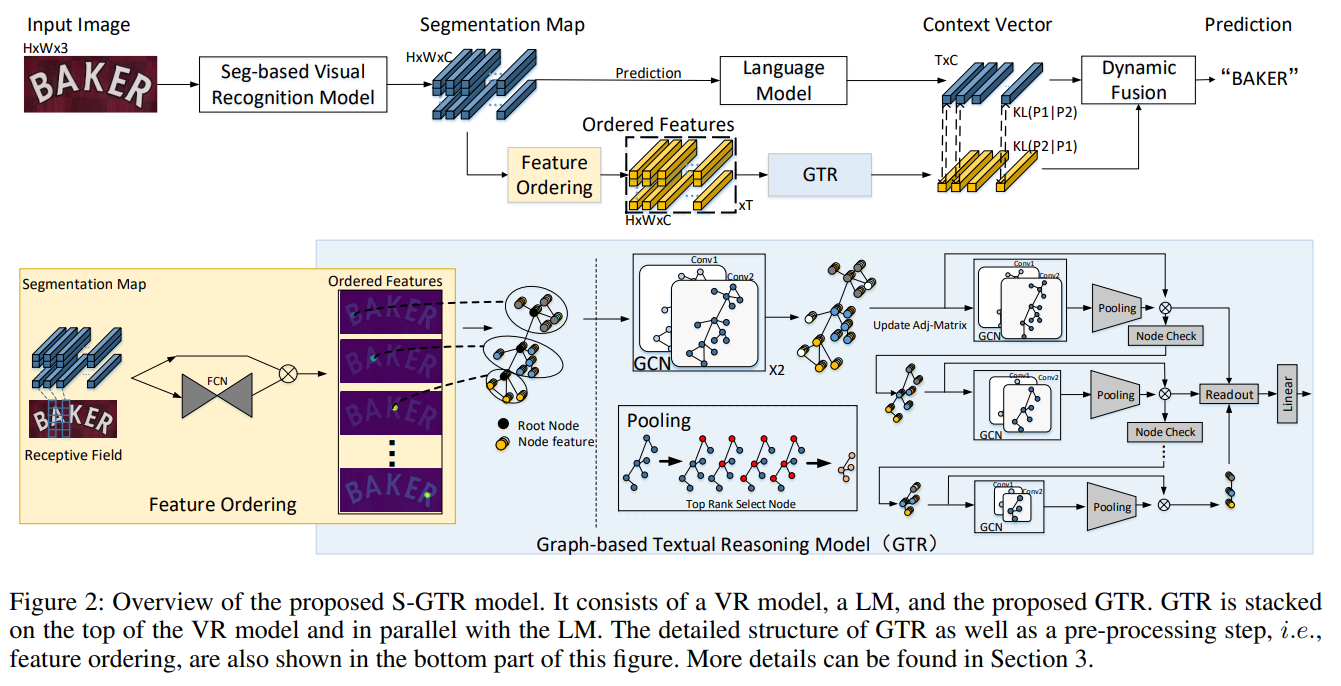
图3:算法的框架图
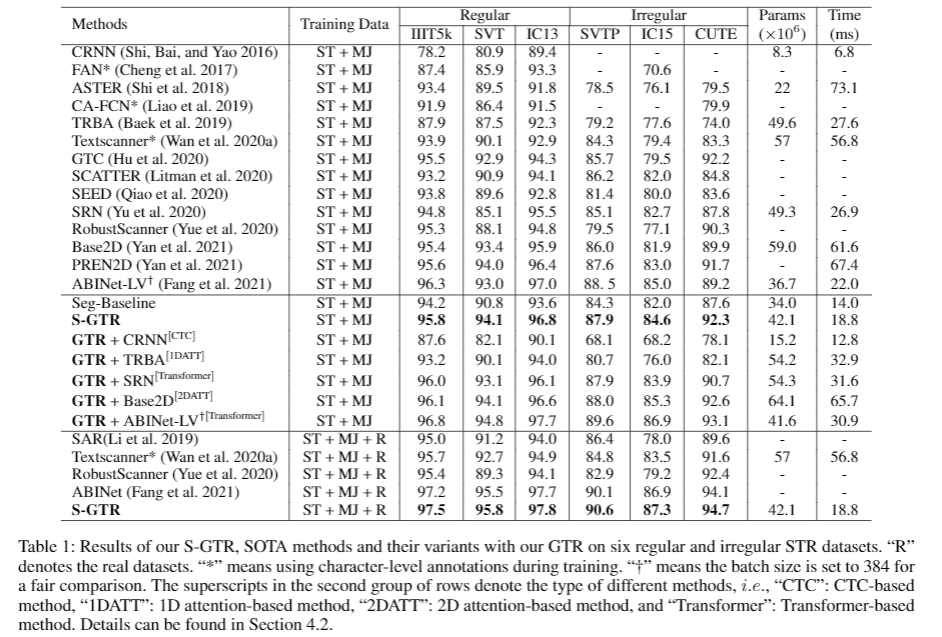
图4:算法的定量结果
论文题目:Resistance Training using Prior Bias: toward Unbiased Scene Graph Generation
作者: Chao Chen, Yibing Zhan, Baosheng Yu, Liu Liu, Yong Luo, Bo Du
论文概述:场景图生成任务是图像理解的一项重要任务,但现有的场景图生成方法大部分都因数据集中存在的严重长尾分布问题而无法取得最优的表现,解决数据长尾分布对模型的影响对于场景图生成任务有重要意义。本文提出一种基于先验偏差的阻力训练方法(RTPB),通过应用基于数据集先验分布的阻力偏差来调控模型的训练,从而抑制数据长尾分布对模型的影响,提升模型对数据集中数据量较少的类别的泛化能力。实验证明了该方法的有效性,在VG数据集上达到了平均召回率指标的SOTA性能,并与现有方法拉开了显著的差距。
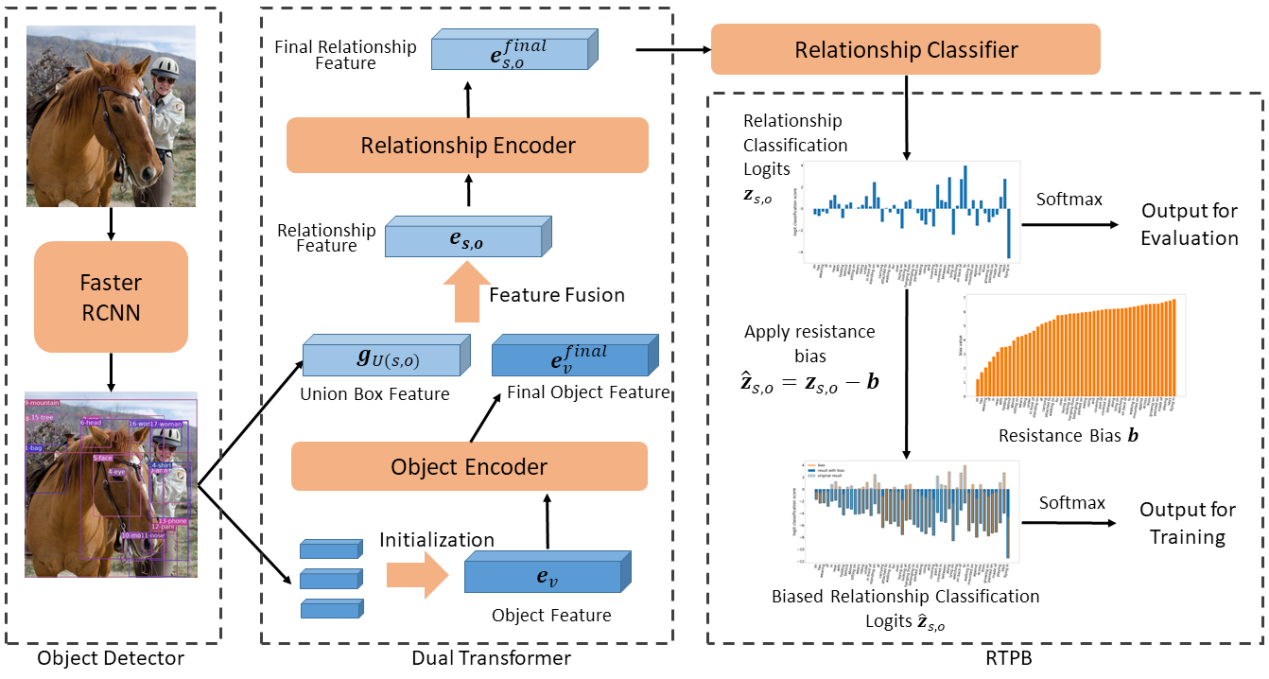
图5:算法的框架图
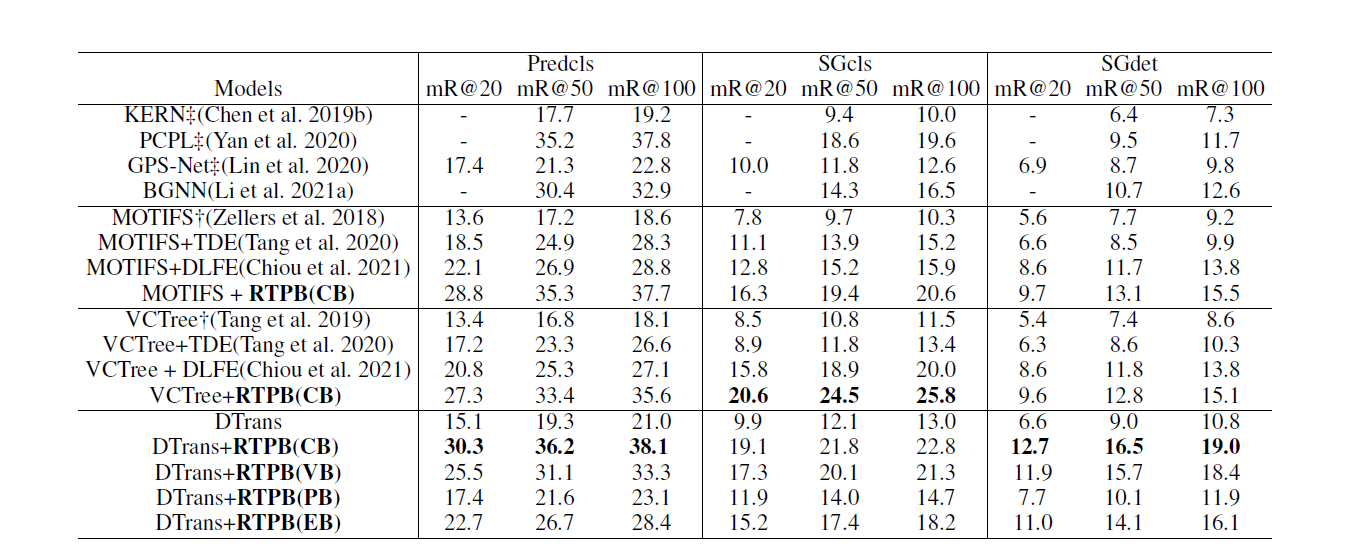
图6:算法的定量结果
Meng Lan, Jing Zhang, Fengxiang He, Lefei Zhang, Siamese Network with Interactive Transformer for Video Object Segmentation. AAAI 2022.
Yue He, Chen Chen, Jing Zhang, Juhua Liu, Fengxiang He, Chaoyue Wang, Bo Du, Visual Semantics Allow for Textual Reasoning Better in Scene Text Recognition. AAAI 2022.
Chao Chen, Yibing Zhan, Baosheng Yu, Liu Liu, Yong Luo, Bo Du, Resistance Training using Prior Bias: toward Unbiased Scene Graph Generation. AAAI 2022.