SIGMA课题组十篇论文被CCF A类会议NeurIPS录用
9月26日,中国计算机学会(CCF)推荐的A类国际学术会议NeurIPS 2024论文接收结果公布。武汉大学计算机学院智能感知与机器学习研究组师生有10篇论文被录用。神经信息处理系统大会(Neural Information Processing Systems,简称NeurIPS)与国际机器学习大会(ICML)、国际学习表征会议(ICLR)并称“机器学习三大顶会”。据悉,第38届NeurIPS会议,将于2024年12月9日-15日在加拿大温哥华会议中心召开。
论文题目:Toward Real Ultra Image Segmentation: Leveraging Surrounding Context to Cultivate General Segmentation Model
作者:Sai Wang, Yutian Lin, Yu Wu, Bo Du
指导老师:武宇教授,林雨恬副教授,杜博教授
论文概述:现有的超大尺度图像分割方法面临两个挑战:一是泛化问题(即现有方法因针对特定数据集设计,缺乏通用分割模型的稳定性和通用性);二是架构问题(即它们与真实世界的超大尺度图像场景不兼容,因为它们在图像尺寸和计算资源之间进行了妥协)。为了解决这些问题,我们重新审视了经典的滑动推理框架,提出了一种环境上下文引导的分割框架(SGNet)用于超大尺度图像分割。SGNet 利用每个图像块周围的更大区域来优化局部图像的分割结果。具体而言,我们提出了一个环境上下文集成模块,以吸收周围的上下文信息并提取对局部图像块有利的特征。值得注意的是,SGNet 可以无缝集成到任何通用分割模型中。我们在五个数据集上的大量实验表明,SGNet 在多种通用分割模型中实现了有竞争力的结果,并大幅超过了传统的超大尺度图像分割方法。
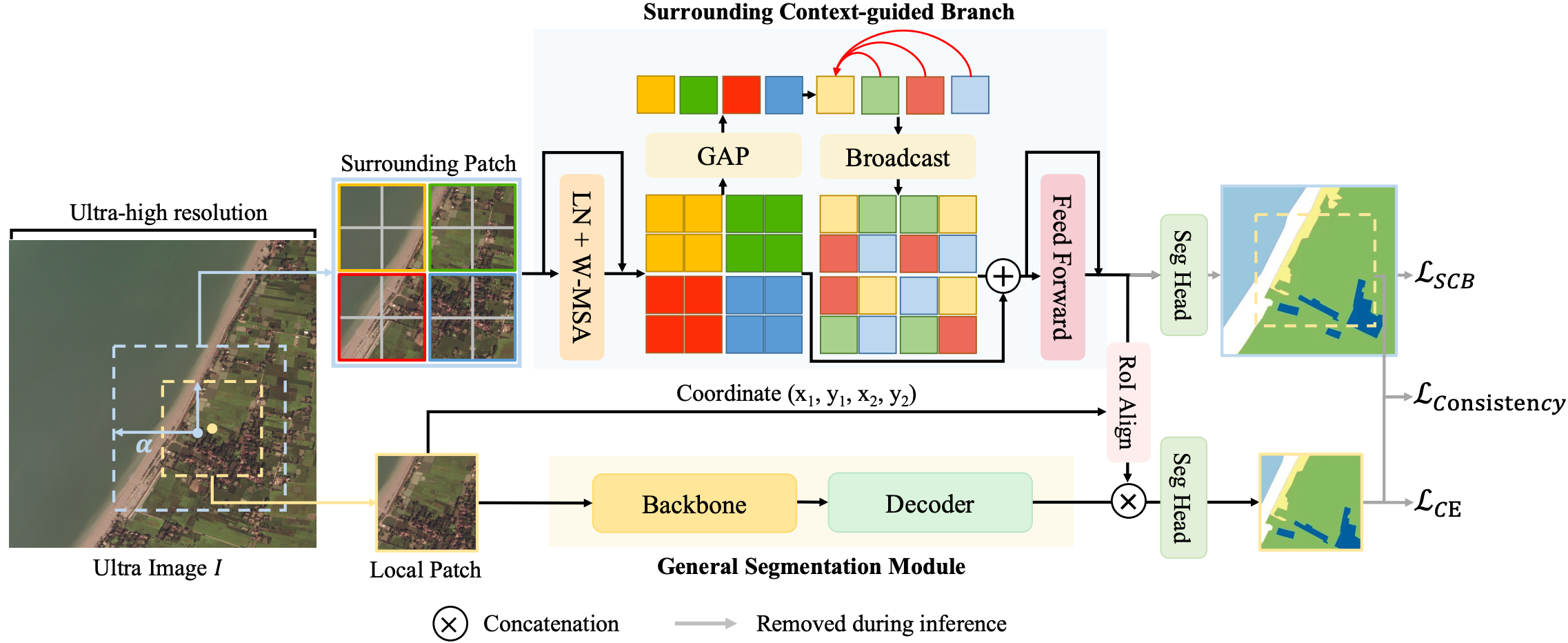 框架
框架
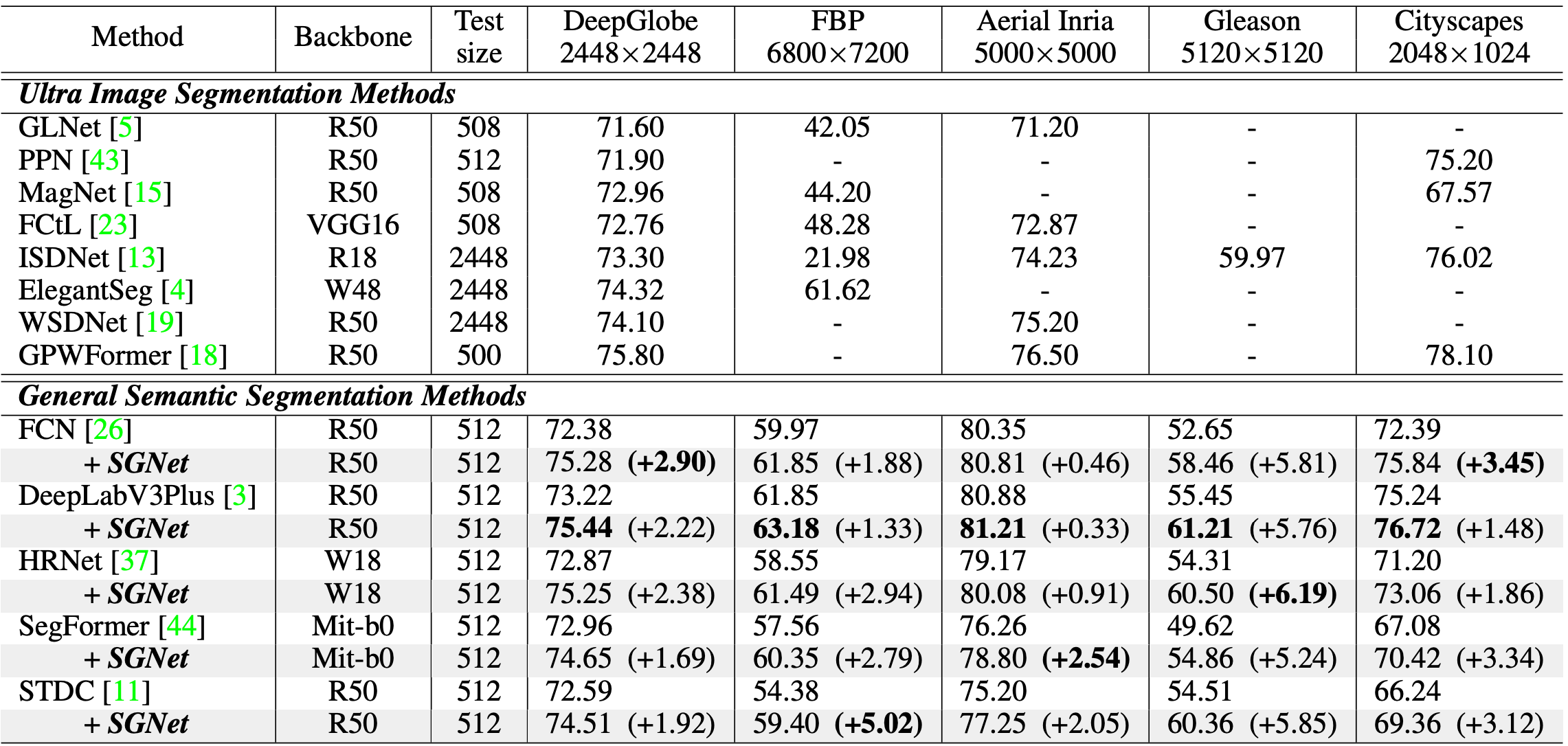 算法性能比较
算法性能比较
论文题目:What If the Input is Expanded in OOD Detection?
作者:Boxuan Zhang, Jianing Zhu, Zengmao Wang, Tongliang Liu, Bo Du, Bo Han
指导老师:王增茂副教授,杜博教授
论文概述:分布外(Out-of-distribution, OOD)检测旨在识别来自未知类别的 OOD 输入,这对于在开放世界中可靠部署机器学习模型非常重要。在此之前,人们提出了各种评分函数,以将OOD数据与分布内(ID)数据区分开来。然而,现有的方法通常侧重于从单一输入中挖掘判别信息,隐式地限制了其表征维度。在这项工作中,我们引入了一个新的视角,即在输入空间采用不同的常见破坏来扩展输入维度。我们揭示了一个有趣的现象,称为置信度突变(Confidence Mutation),即在相同破坏类型下,OOD 数据的置信度会显著下降,而 ID 数据因其在语义特征上的抗干扰性而具有更高的置信度期望。 在此基础上,我们正式提出了一种新的评分方法,即置信度平均评分法(Confidence aVerage,CoVer),它可以通过简单地平均从不同的损坏输入和原始输入中获得的OOD评分来捕捉其中的动态差异,从而使 OOD 和 ID 分布在检测任务中更加可分。我们进行了大量的实验和分析以了解和验证 CoVer 的有效性。
 框架
框架
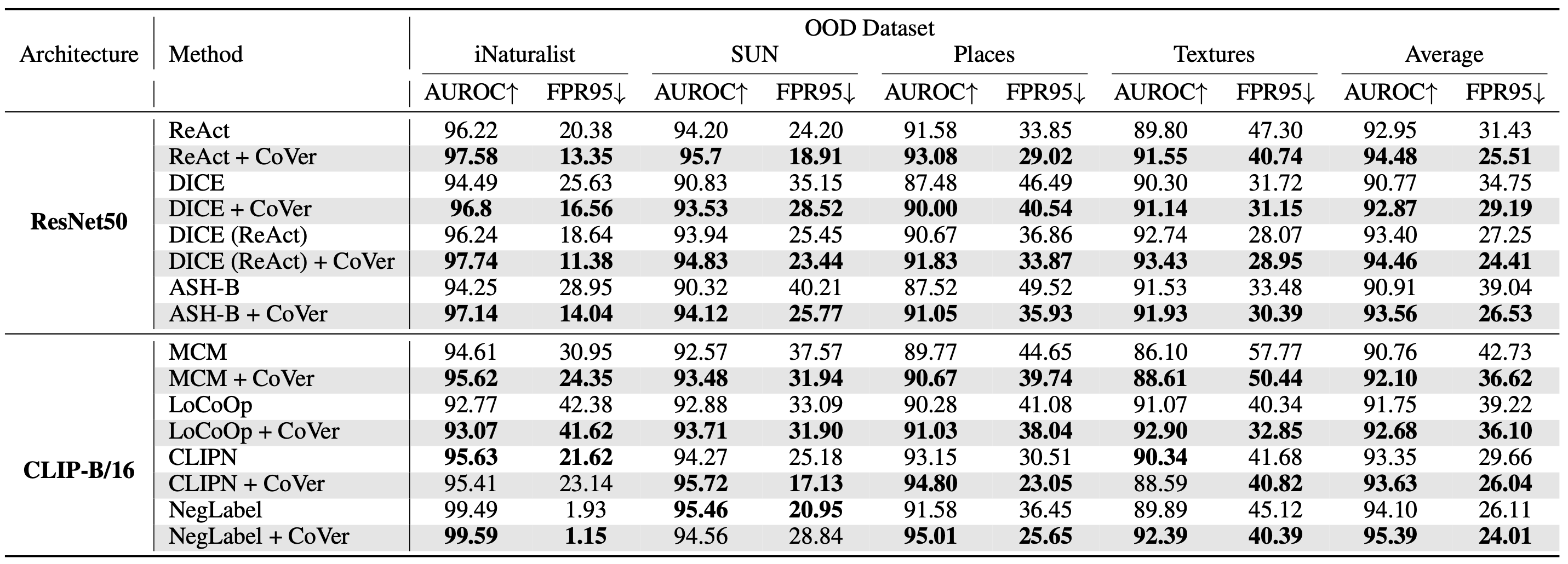 算法性能比较
算法性能比较
论文题目:Parameter Disparities Dissection for Backdoor Defense in Heterogeneous Federated Learning
作者:Wenke Huang, Mang Ye , Zekun Shi, Guancheng Wan, He Li, Bo Du
指导老师:叶茫教授、杜博教授
论文概述:后门攻击对联邦学习系统构成了严重威胁,其中恶意客户端通过优化触发的分布来误导全局模型朝向预定目标。现有的后门防御方法通常需要同质性假设、验证数据集或客户端优化冲突。在我们的工作中,我们观察到良性异构分布与恶意触发分布在参数重要性程度上表现出明显差异。我们引入了费雪差异聚类和重放方法,该方法利用费雪信息来计算本地分布的参数重要性程度。通过这种方式,我们能够重新加权客户端的参数更新,并将具有较大差异的更新识别为后门攻击者。此外,我们优先对重要参数进行重新缩放,以加速对目标分布的适应,鼓励关键参数发挥更大作用,同时减弱次要参数的影响。这种方法使提出的方法能够在异构联邦学习环境下应对后门攻击。在各种异构联邦场景中的实验结果表明了该方法在应对后门攻击时的有效性。
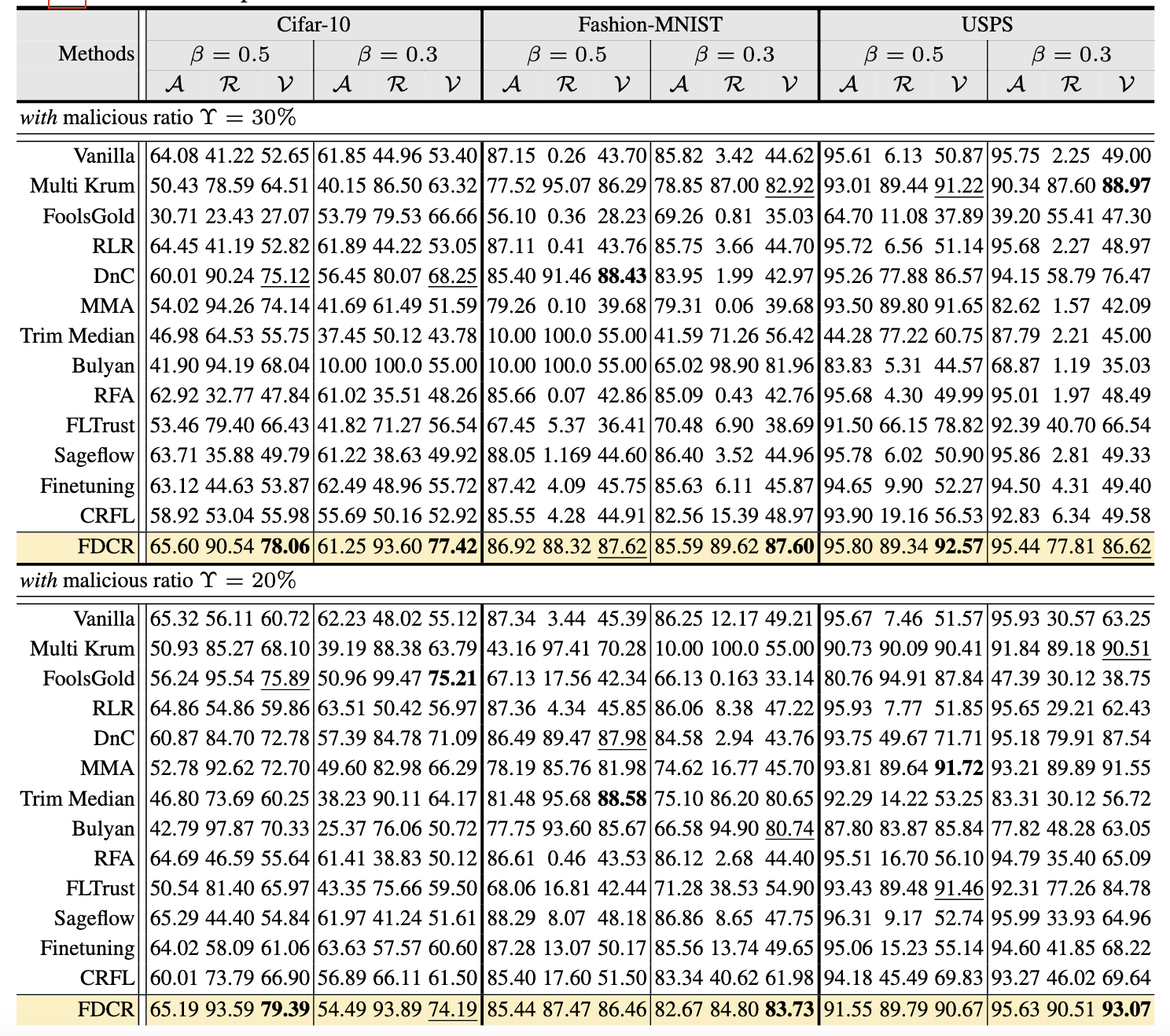 算法性能比较
算法性能比较
论文题目:ROBIN: Robust and Invisible Watermarks for Diffusion Models with Adversarial Optimization
作者:Huayang Huang, Yu Wu, Qian Wang
指导老师:武宇教授
论文概述:对生成内容进行水印嵌入是内容认证、所有权保护和缓解潜在滥用的重要工具。现有的水印方法面临着在保持鲁棒性和实现隐蔽性之间寻求平衡的难题。这些方法经验式地在不影响可见性的前提下注入鲁棒的水印,并通过限制水印的强度被动地实现隐蔽性,进而牺牲了水印的鲁棒性。在本文中,我们显式地引入水印隐藏过程以主动实现隐蔽性,从而允许嵌入更强的水印。具体而言,我们在扩散生成的中间状态植入一个鲁棒的水印,然后引导模型在最终生成的图像中巧妙隐藏该水印。我们采用对抗优化算法为每个水印生成最佳隐藏提示引导信号。该提示向量经过优化,旨在最大限度地减少生成图像中的伪影,而水印则经过优化以达到最大强度。通过逆转生成过程可以验证水印。在多种扩散模型上的实验表明,即使图像经历了严重的篡改,水印仍然可验证,并且与其他最先进的鲁棒水印方法相比,具有更优的隐蔽性。
 框架
框架
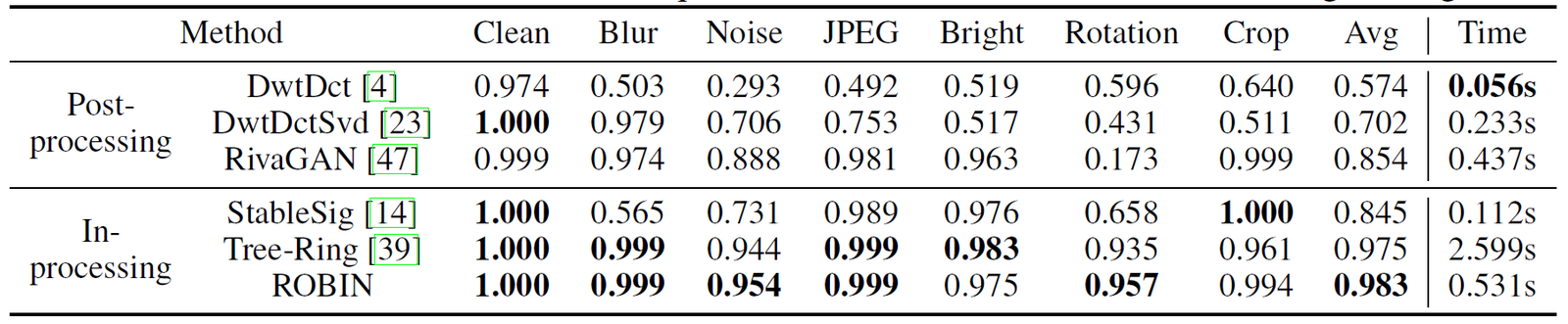 算法性能比较
算法性能比较
论文题目:Prospective Representation Learning for Non-Exemplar Class-Incremental Learning
作者:Wuxuan Shi, Mang Ye
指导老师:叶茫教授
论文概述:非样本类增量学习是一项具有挑战性的任务,它需要在不保留任何旧类样本的情况下同时识别新旧类。以往的工作主要是在新的任务到来的时候,对新旧类之间的冲突进行回溯。然而,旧任务数据的缺乏使得平衡新旧班级变得困难。相反,我们提出了一种前瞻性表征学习方法PRL来让模型为处理冲突提前做好准备。在初始阶段,我们压缩当前类的嵌入分布,为未来类的向前兼容预留空间。在增量阶段,我们在更新模型时,使新的类特征与保存的旧类原型在潜在空间中分离,同时将当前嵌入空间与潜在空间对齐。因此,新的类特征被聚集在预留的空间中,以最小化新类对先前类的干扰。我们的方法可以帮助现有的NECIL基线以即插即用的方式平衡新旧类。在四个基准测试上的大量实验表明,我们的方法比最先进的方法表现出更好的性能。
论文题目:FedSSP: Federated Graph Learning with Spectral Knowledge and Personalized Preference
作者:Zihan Tan, Guancheng Wan, Wenke Huang, Mang Ye
指导老师:叶茫教授
论文概述:个性化联邦图学习在不牺牲隐私的前提下,促进了图神经网络的去中心化训练,同时满足了非独立同分布参与者的个性化需求。在跨领域场景中,结构异质性给联邦图学习带来了显著挑战。然而,以往的研究错误地在全球范围内共享了非通用知识,未能在域结构变化下提供本地个性化解决方案。我们创新性地揭示了域结构变化可以通过图的谱性质很好地反映出来。相应地,我们的方法通过共享通用的频谱知识来克服这一问题。此外,我们指出了图结构中存在的偏差消息传递机制,并提出了个性化偏好模块。结合这两种策略,实现了有效的全球协作与个性化本地应用,并且在跨数据集和跨领域的设置中进行了大量实验,证明了我们方案的优越性。
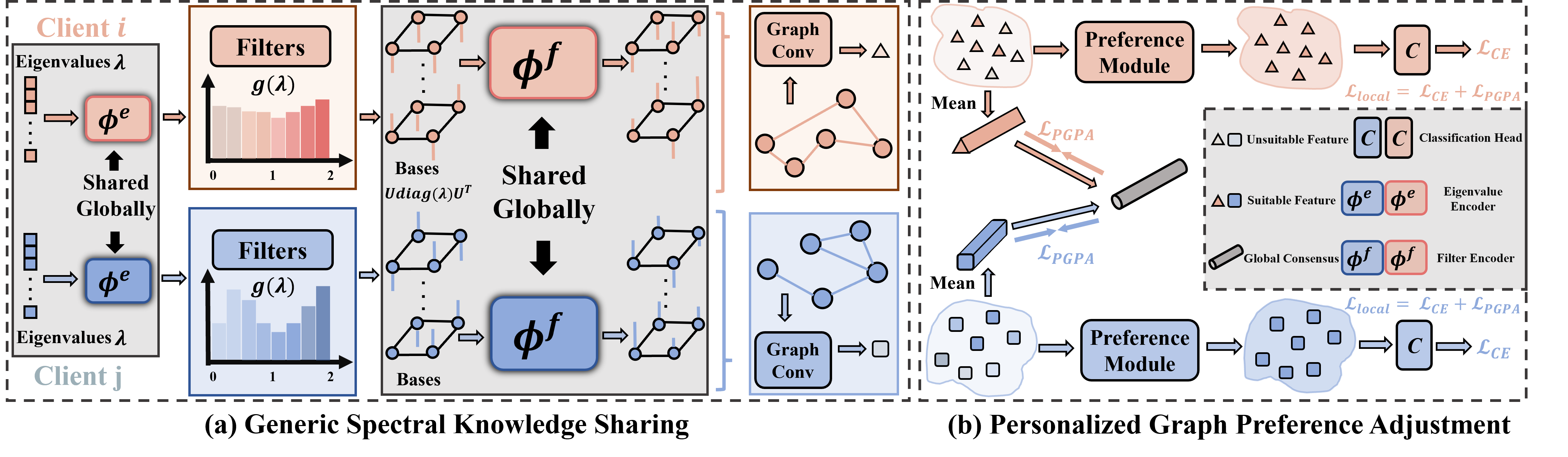 框架
框架
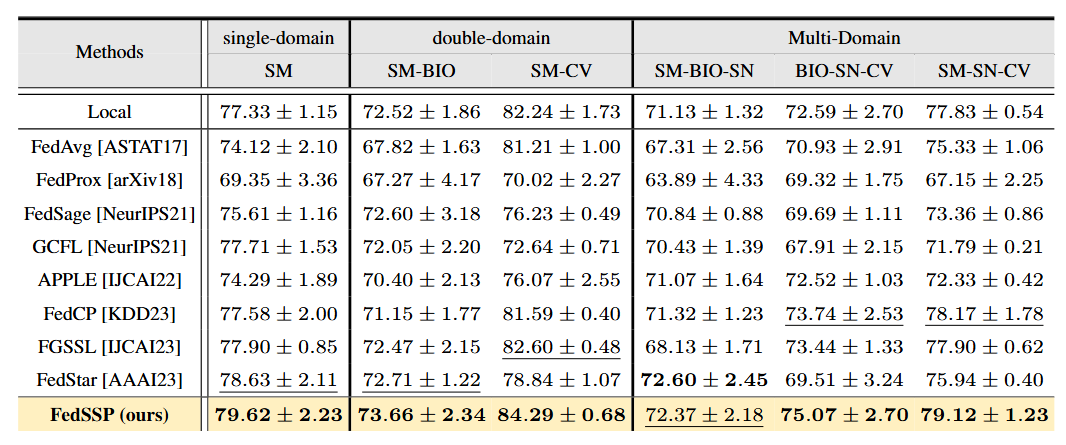 算法性能比较
算法性能比较
论文题目:InfoRM: Mitigating Reward Hacking in RLHF via Information-Theoretic Reward Modeling
作者:Yuchun Miao, Sen Zhang, Liang Ding, Rong Bao, Lefei Zhang, Dacheng Tao
指导老师:张乐飞教授
论文概述:尽管从人类反馈中进行强化学习在使语言模型与人类价值观对齐方面取得了成功,但奖励黑客攻击(也称为奖励过度优化)仍然是一个关键挑战。这个问题主要源于奖励泛化错误,即奖励模型使用与人类偏好无关的虚假特征来计算奖励。在本工作中,我们从信息论的角度解决这个问题,并通过引入变分信息瓶颈(IB)目标,提出了一个用于奖励建模的框架,称为InfoRM,以过滤掉无关信息。值得注意的是,我们进一步发现了InfoRM的IB潜在空间中的过度优化与异常值之间的相关性,证明了其作为检测奖励过度优化的有前景工具。受到这一发现的启发,我们提出了簇分离指数(CSI),该指数通过量化IB潜在空间中的偏差,作为奖励过度优化的指标,以促进在线缓解策略的发展。在广泛的设置和不同规模的模型(70M、440M、1.4B和7B)上的大量实验表明了InfoRM的有效性。进一步的分析揭示了InfoRM的过度优化检测机制不仅有效,而且在广泛的数据集上表现出良好的稳健性。
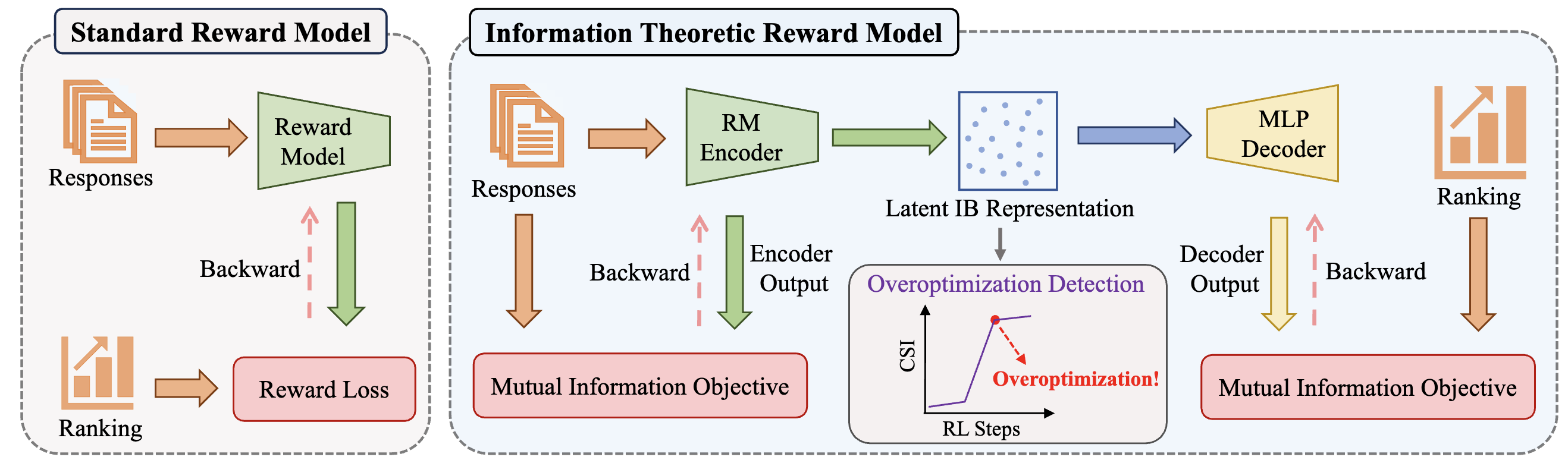 框架
框架
 算法性能比较
算法性能比较
论文题目:GoMatching: A Simple Baseline for Video Text Spotting via Long and Short Term Matching
作者:Haibin He, Maoyuan Ye, Jing Zhang, Juhua Liu, Bo Du, Dacheng Tao
指导老师:刘菊华教授,杜博教授
论文概述:视频文本提取 (video text spotting) 包括了文本检测 (text detection) 、文本识别 (text recognition) 以及文本跟踪 (text tracking) 三个任务。尽管先前基于端到端训练的方法展现出值得称赞的性能,但多任务联合优化可能会给单个任务带来次优结果的风险。在本研究中,我们发现了最先进的视频文本提取模型的一个主要瓶颈:识别性能不足。为了解决这个问题,我们将一个现成的基于query的图像文本提取器 (image text spotter) 有效地转变为视频文本提取器 (video text spotter),并提出了一个简单而高效的基线,称为GoMatching。该基线通过冻结图像文本提取器并将训练重心放在跟踪器上,从而实现在避免多任务优化冲突的同时,保持图像文本提取器强大的识别能力。为了使图像文本提取器能够适应视频数据集,我们引入了一个重评分头 (rescoring head),通过对每个检测到的文本实例的置信度进行重新计算和调整,以此生成更好的跟踪候选池。此外,我们设计了一个长-短期匹配模块,称为LST-Matcher,借助Transformer整合长期和短期匹配结果来增强跟踪器的跟踪能力。基于上述简单的设计,GoMatching在ICDAR15-video、DSText、BOVText三个公开数据集以及我们构建的任意形状文本测试集ArTVideo上,性能均显著超过了先前的方法,并且有效降低了大量的训练成本。
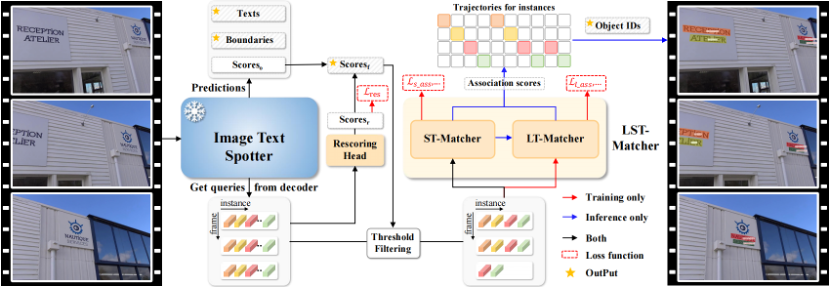 框架
框架
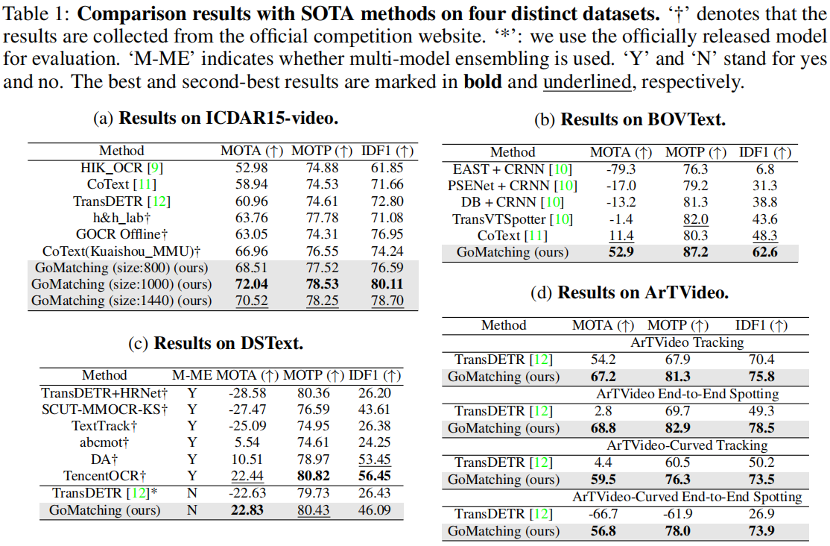 算法性能比较
算法性能比较
代码链接: https://github.com/Hxyz-123/GoMatching
论文链接: https://arxiv.org/abs/2401.07080
论文题目:Empowering Visible-Infrared Person Re-Identification with Large Foundation Models
作者:Zhangyi Hu, Bin Yang, Mang Ye
指导老师:叶茫教授
论文概述:传统的可见光-红外行人重识别(VI-ReID)方法,由于红外模态信息缺失所导致的模态差异,性能通常低于仅使用RGB图像的ReID方法。为了解决这一问题,我们提出了一种由目击者文本辅助的跨模态检索任务。基础模型(大型语言模型(LLMs)和视觉语言模型(VLMs))的发展,启发我们探索将其应用于VI-ReID的可行方式以解决现有问题。基于此,我们提出了一个基础模型驱动的文本增强 VI-ReID框架(TVI-FM),其核心思想是利用VLMs自动生成的文本描述,来丰富红外模态的表示。首先使用两个微调的VLM从红外和可见光图像中生成文本描述,再由LLM进行增强。为了利用生成的文本丰富红外特征,用一个预训练的VLM抽取与对应视觉模态大致对齐的红外/可见光描述文本特征, 再融合文本空间中的红外-可见光特征差异与红外特征得到语义等同于可见光模态的初步融合模态。然后,先训练好并冻结一个VI-ReID骨干模型的参数,利用其抽取视觉特征,再增量地通过模态联合学习微调文本编码器,使文本编码器能够有效地从视觉特征中学习互补信息,有效地减少融合模态与可见模态之间的差异。此外,通过在推理时利用各查询模态的互补优势进行模态集成检索,我们进一步提高了检索的性能和鲁棒性。广泛的实验表明,所提出方法在三个扩展的跨模态再识别数据集上取得了有竞争力的性能,为在下游具有大数据量需求的多模态任务中应用基础模型提供了一种新的解决思路。
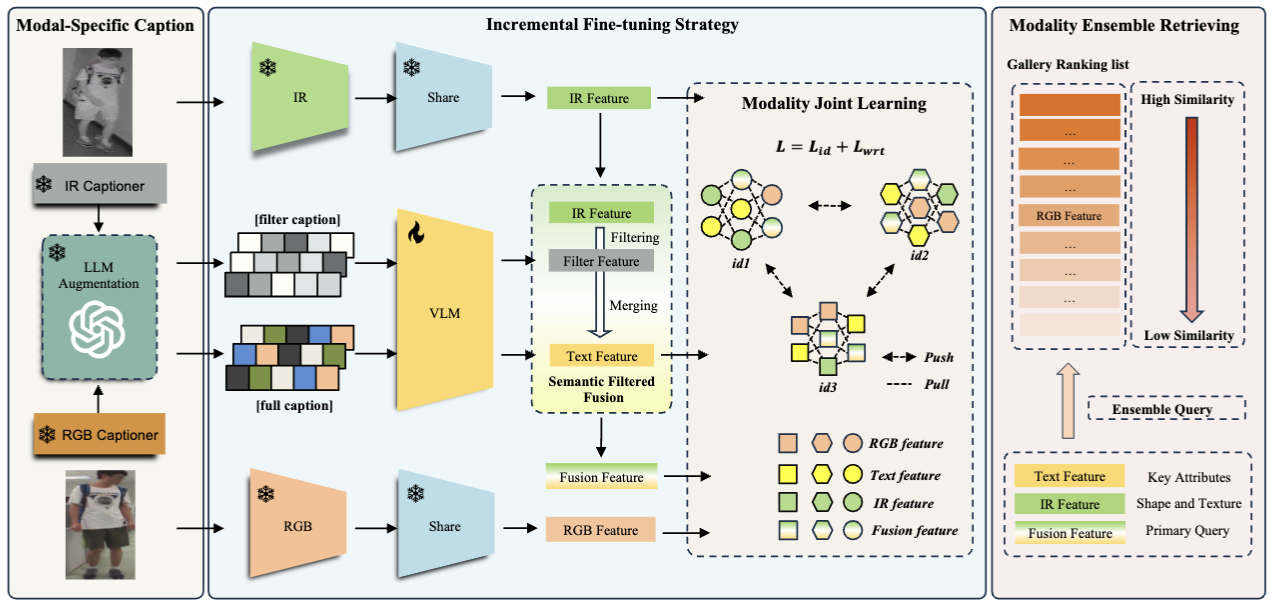 框架
框架
 算法性能比较
算法性能比较
论文题目:Reference Trustable Decoding: A Training-Free Augmentation Paradigm for Large Language Models
作者:Luohe Shi, Yao Yao, Zuchao Li, Lefei Zhang, Hai Zhao
指导老师:李祖超副研究员,张乐飞教授
论文概述:尽管大语言模型(LLMs)以其在多种下游任务上出色的表现成为了现在语言模型的主流,但对其在特定下游任务上进行适应仍然是一个十分昂贵的过程。传统方法分为上下文学习(ICL)与参数高效微调(PEFT)两类。ICL方法尽管不需要编辑模型参数,也就是说不涉及反向传播,但其增加的上下文长度会大幅度拖慢模型的推理速度,造成持续的成本增加。而PEFT方法,尽管其中大部分在推理时不涉及额外的运算量,但是其因为涉及到了反向传播,在训练时需要存储大量的中间状态,导致对硬件要求较高。为了解决这些问题,我们提出了参考可信解码(RTD),旨在不对模型进行反向传播的同时快速增强模型在下游任务上的性能,同时只引入最少量的训练与推理的额外成本。RTD通过构建一个外置的数据库,针对模型最后的LM_Head层进行调整。RTD可以将当前输入与数据库中的上下文快速比对,并通过其中的额外信息来改变从隐藏状态到词表的映射模式,在只引入较低的额外成本的情况下加强在指定下游任务上的解码的过程。我们在多个不同尺寸的模型和多种不同针对的下游任务上测试了RTD的性能,其均取得了更优的表现。除此以外,RTD与传统方法(ICL, PEFT)均展示了良好的正交性,通过嵌套使用可以得到持续的性能提升。
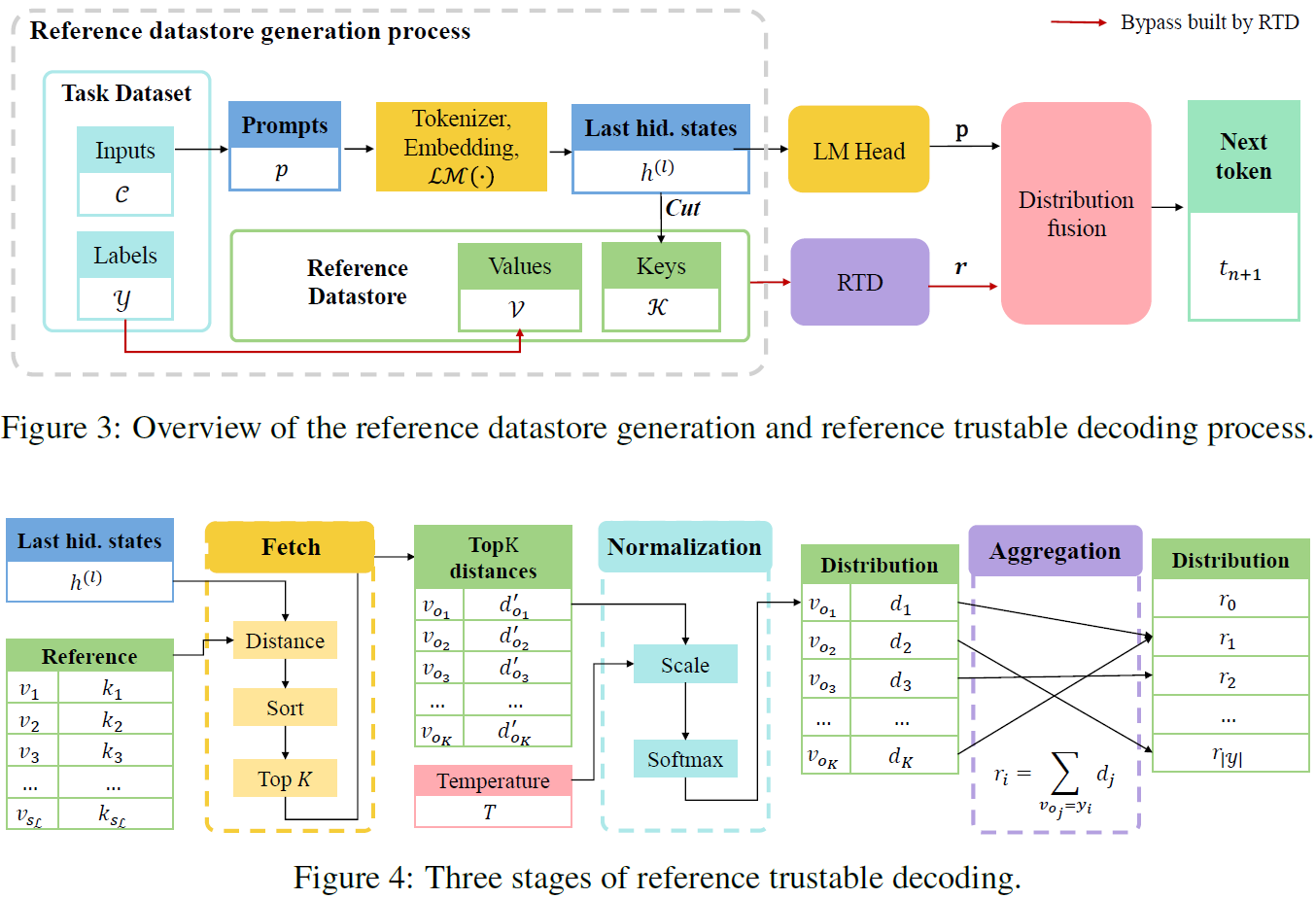 框架
框架
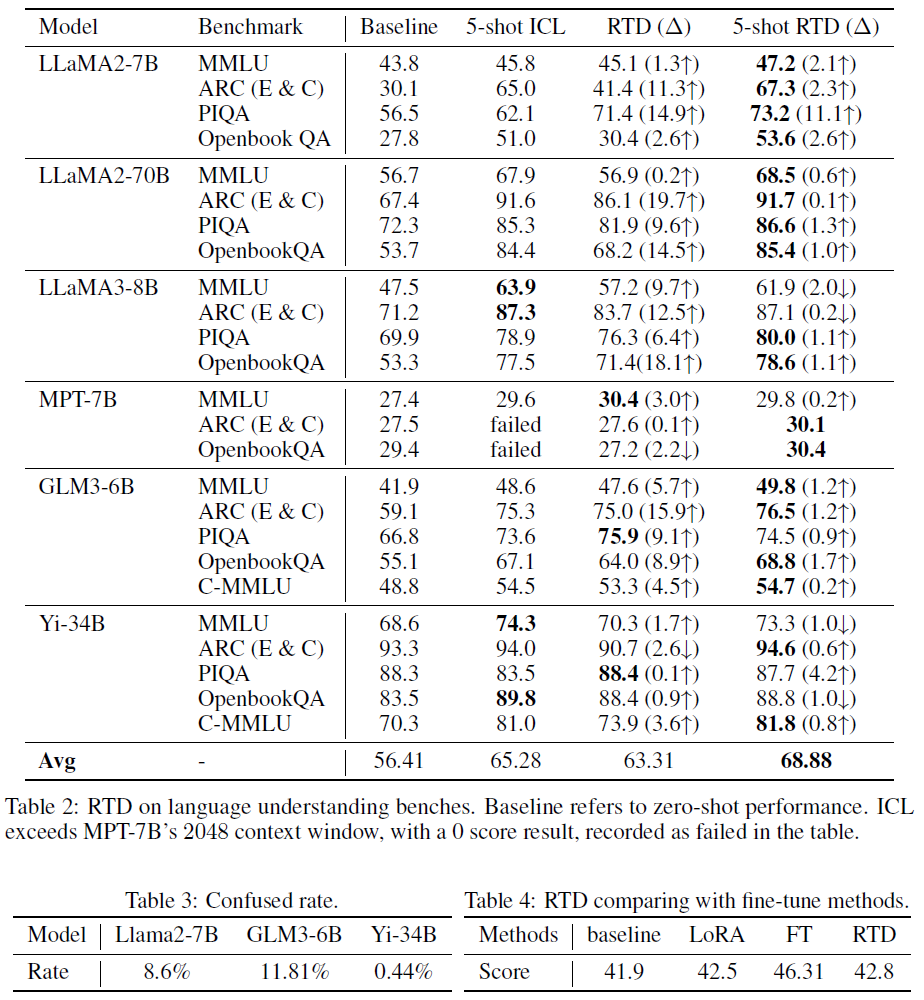 算法性能比较
算法性能比较