传统监督模型的泛化性能依靠标记样本的数量和质量决定。然而对于数据进行标注需要领域内有经验的专家手工进行,这使得获取标记样本的代价十分昂贵。因此,在现实世界各领域的实际问题中,标记样本的缺乏是普遍存在的。为了解决这个问题,主动学习通过查询函数主动地挑选高质量的样本进行标记,在减少标记样本花费的同时获得泛化能力强的模型。主动学习的流程如下:学习者通过少量初始标记样本开始学习,利用一定的查询函数选择出一个或一批最有用的样本,并向标注员询问标签,然后利用获得的新知识来训练模型和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。
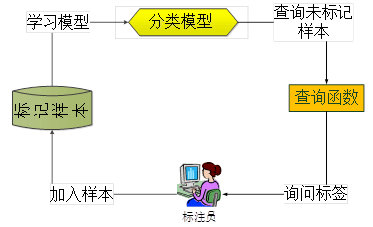
在主动学习技术各环节中,查询函数是最为基本和最为重要的环节,它决定了如何从未标记的候选样本中选取样本。在主动学习方法的研究中,各种主动学习方法的主要差异就在于查询函数的设计。
查询函数遵循不确定性准则与差异性准则。不确定性准则查询不确定性大的样本,因为此类样本含有丰富的信息量,能够为模型性能的提升提供帮助;差异性准则查询一批冗余度小的样本,避免信息重复。现在结合如下一种经典的主动学习方法来说明不确定性准则与差异性准则在主动学习中的应用。
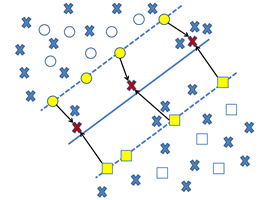
基于最近支持向量的边缘抽样【1】是一种基于支持向量机的主动学习方法。它一方面选择最靠近分类超平面的样本;另一方面增加限制条件,使得每次迭代中加入的样本不可能拥有相同的最近支持向量,因为我们可以认为共享同一最近支持向量的样本是相似的。这样既可以查询信息量丰富的样本,又可以有效地避免查询相似的样本,减少信息冗余。
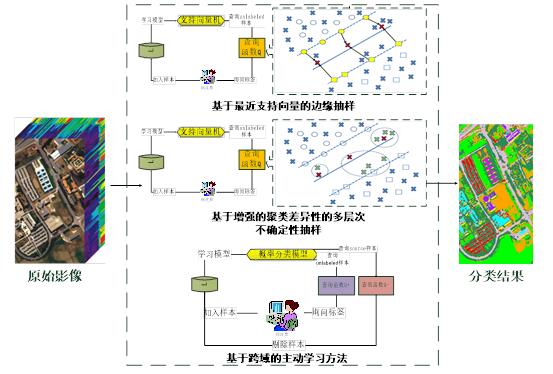
主动学习在高光谱遥感影像分类和医学影像分类中得到了广泛应用。图3为主动学习在高光谱遥感影像分类中的应用。对于高光谱遥感影像的分类而言,一个至关重要的成功因素是充足的训练样本,然而在实际应用中,标记样本的数量往往是有限的,而且人工标注样本需要耗费大量的人力、财力和时间。利用主动学习解决高光谱遥感影像分类中标记样本不足的问题。经过主动学习后,形成了较小规模且较高质量的训练集。使用获得的训练集进行训练可以得到泛化能力较强的模型。
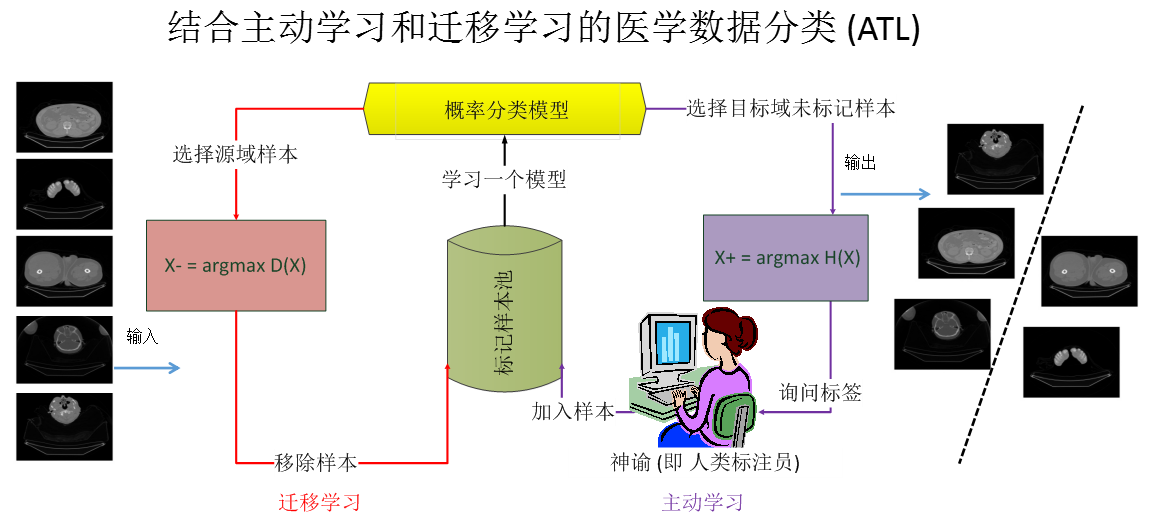
下图为主动学习在医学影像分类中的应用。随着计算机技术和医学影像技术的发展,各种形态的医学影像(如CT,MRI,PET,X光等)数据被大量的获取以及存储。医学影像数据能够良好地辅助医学诊断。面对大量的医学影像数据,利用计算机技术进行数据挖掘和数据分析显得尤为重要。医学影像分类是对医学影像数据进行分析的一个关键问题,从医学应用的角度来说,它的目的是依据特诊将原始影像进行归类,为临床诊断提供依据。然而对于医学影像数据进行标注需要有经验的医生或者专家手工进行,因此获取带有标记的医学影像样本的代价比较昂贵。在医学影像分类任务中,标记样本的缺乏是普遍存在的。以下应用结合主动学习和迁移学习来解决医学影像分类中标记样本不足的问题。利用主动学习在目标域中查询高质量的未标记样本,向医生或者专家询问标签后加入训练集合;同时利用迁移学习查询源域中与目标域不一致的样本,将其从训练集合中删除。使得在较少目标域标记样本的情况下训练出具有较强泛化能力的分类模型,提高医学影像分类的精确度。
 【1】Tuia D, Ratle F, Pacifici F, et al. Active learning methods for remote sensing image classification[J]. Geoscience and Remote Sensing, IEEE Transactions on, 2009,47(7):2218-2232.
【1】Tuia D, Ratle F, Pacifici F, et al. Active learning methods for remote sensing image classification[J]. Geoscience and Remote Sensing, IEEE Transactions on, 2009,47(7):2218-2232.